Summary In short, it's not the same as the AI ​​you learned before. Beijing time on March 9th at 12:00, a world-famous Go "Human Machine World War" was staged in Seoul, South Korea. The artificial intelligence developed by Google for the company...
In short, it's not the same as the AI ​​you learned before. Beijing time on March 9th at 12:00, a world-famous Go "Human Machine World War" was staged in Seoul, South Korea. One side of the competition is the artificial intelligence program AlphaGo developed by Google, and the other side is the world champion of Go, and the famous Korean star Li Shishi.
After three and a half hours of fighting, Li Shishi’s nine-stage voter conceded defeat and lost the first of the five games.
Regardless of the end result, the future has arrived!
There are 8 questions you need to know about this century war.
1. Why study Go AI? Why is Go, is it something else?
The game is one of the main battlefields that AI originally developed. Game games require AI to be smarter, more flexible, and solve problems in a way that is closer to human thinking. The development of game AI can be traced back to a doctoral thesis in 1952. In 1997, chess AI defeated top humans for the first time; in 2006, humans defeated the top chess AI for the last time. The top human intelligence touchstone in the European and American traditions was finally defeated in front of the computer, and it was predicted by computer scientists more than 40 years ago.

In 1997, in New York, when playing against the end of the IBM Deep Blue computer, Gary Kasparov on a TV monitor.
But there is a game that has always been the patent of the human brain - the ancient Go. Go AI has been struggling for a long time, and the top AI can't even beat a slightly stronger amateur. This also seems reasonable: in chess, there are 35 possibilities per round, and a game of chess can have 80 rounds; in contrast, Go has 250 possibilities per turn, and a game can be up to 150 rounds. This huge amount is enough to discourage any brute-force exhausted person - and humans, we believe, can skip the brute force with some algorithm that is difficult to copy, and see the essence of the chessboard at a glance. However, no matter how people think, this situation certainly cannot last forever. 2. Studying chess AI, do you need a high level of chess for researchers?
No need. Behind AlphaGo is a group of outstanding computer scientists, specifically experts in the field of machine learing algorithms . Scientists use neural network algorithms to input the game records of chess experts to the computer, and let the computer compete with itself, and continue to learn training in the process. To some extent, AlphaGo's chess is not taught by the developers, but self-taught.

Alpha dogs also have a huge flaw: no hands. On the left is one of the makers of the Alpha dog, responsible for the completion of the action.
However, Demis Hassabis, the founder of AlphaGo (Deepmind), was indeed a fanatic of chess. Hassabis began to get involved in chess at the age of four and soon evolved into a prodigy. . It is the interest in the game of the game that makes Hassabis begin to think about two important questions: how does the human brain deal with complex information? More importantly, can computers be like humans? During the Ph.D., Kasabis chose to study cognitive neuroscience and computer neuroscience. Today, the 38-year-old Hasabis, with his AlphaGo, launched an offensive against Go, one of the top human game games. 3. How does AlphaGo play chess?
At the heart of AlphaGo are two different deep neural networks. "policy network" and "value network". Their mission is to collaborate to “pick out†those promising moves and discard the obvious bad moves, thus keeping the amount of computation within the range that the computer can do—essentially, what human players do.
Among them, the “value network†is responsible for reducing the depth of the search – the AI ​​will judge the situation while calculating, and when the situation is obviously inferior, it will directly abandon certain routes and not count the blacks;
The "strategy network" is responsible for reducing the width of the search - in the face of a game of chess, some moves are obviously not to go, such as not being sent to others.
AlphaGo uses these two tools to analyze the situation and determine the pros and cons of each sub-strategy, just as human players will judge the current situation and infer the future. In this way, AlphaGo can determine where the probability of winning is higher when analyzing, for example, the next 20 steps.
4, today AlphaGo and the past dark blue, who is more powerful?
Let's first look at the difference between Go and Chess:
First, there are many possible ways for Go in each step: the Go player has 19X19=361 kinds of drop selection when starting, and there are hundreds of possible ways at any stage of the game. But there are usually only about 50 possible ways to play chess. Go has a maximum of 3^361 situations, which is about 10^170, and the number of atoms in the observed universe is only 10^80. Chess has a maximum of 2^155 situations, called the Shannon number, which is roughly 10^47.
Second, for chess, you only need to calculate the sum of the values ​​of the remaining pieces on the current board, and you can probably know who is on the board. However, this method does not work for Go. In the chess game, it is difficult for the computer to distinguish between the dominant side and the weak side of the current game.
It can be seen that playing chess is also much more difficult than dealing with chess.
Let us take a visual look at the complexity of chess and Go. The picture above is chess and the picture below is Go:
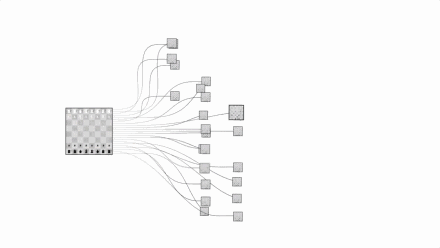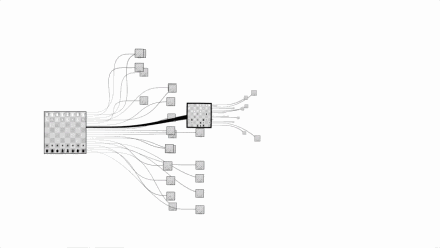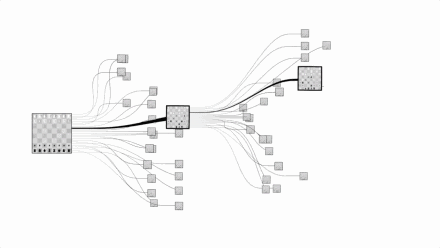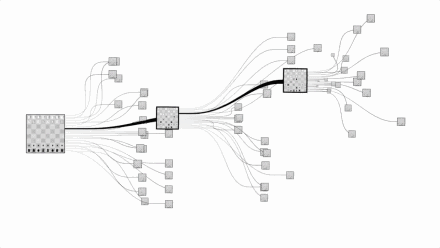
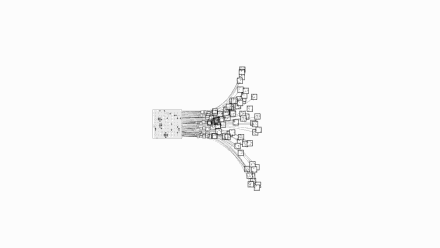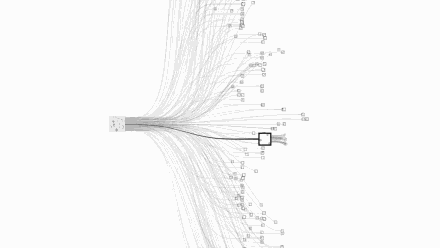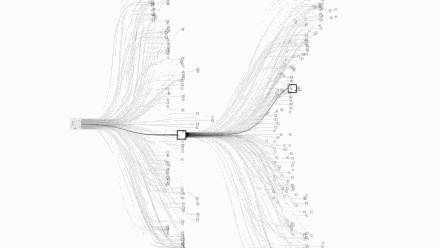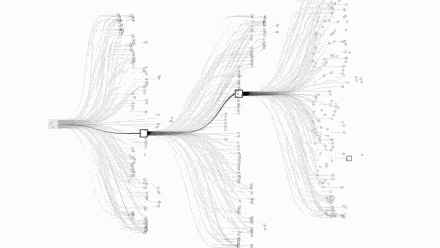
Images are from Google
In addition, dark blue is specially made for chess. It evaluates the standard of the disk completely depends on the rules of chess itself. It can't do anything other than playing chess. Even the five-game chess will not! But AlphaGo is different, Go is just one of his testing platforms. Engineers can develop and test AlphaGo's capabilities through Go. This ability will be applied to various fields in the future. Like StarCraft or NPC in role-playing games, advanced artificial intelligence can not only become a strong opponent, but also become a good teammate. 5. Is there any limit to AlphaG's super learning ability?
For this question, Kevin Curran, a professor of computer science at the University of Manchester in the UK, expressed a negative attitude. He believes that we have no reason to believe that technology will have limits, especially in specific areas like AlphaGo.
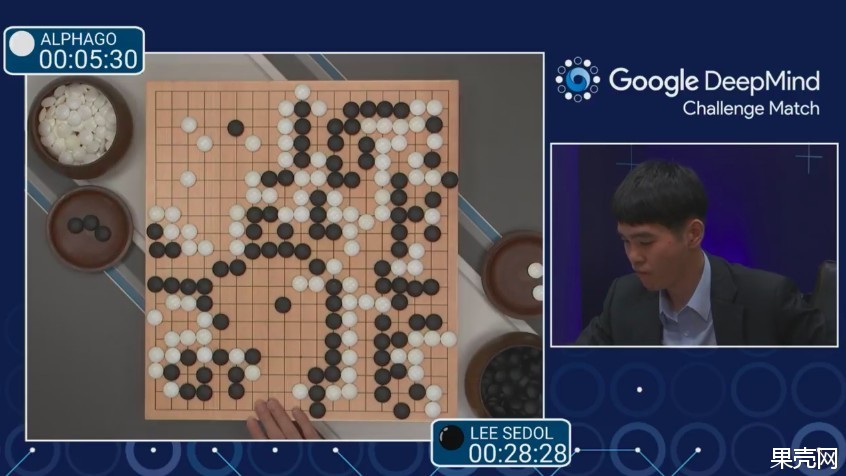
The final time of the game. After that, Li Shishi voted to concede.
The two experts from the Department of Computer Science of Nanjing University, Zhou Zhihua and Yu Yang, both believe that the upper limit is objective. Zhou Zhihua said that the key to the effectiveness of "enhanced learning" is that both models are good and have enough "differences". When the performance of the model is improved, the difference will be significantly reduced. To a certain extent, performance will inevitably continue to improve through this mechanism. The upper limit depends on the number of high-quality “marked†samples (equivalent to the real Li Shishi level player's game). Yu Yang’s point of view is that the upper limit does not only exist, but it is already very close to AlphaGo’s current level. According to AlphaGo's report, DeepMind is already trying to avoid overfitting (ie, getting worse and worse), which means they may have reached the upper limit.
6. If AlphaGo beat Li Shishi 5:0 in all 5 innings, what does it mean for artificial intelligence?
As stated at the beginning of this article, the future has arrived. No matter what the final result, it can't stop more humans from finally looking at the AI ​​with vigilant eyes... Liu Jing's comment on the eight-part Go game is: "It's too late to react, everything seems to be too fast! Faceless expression Alpha dog, even the toilet is not on, is the terminator of Go in 4000 years coming today? The air is filled with the taste of the machine."
Humans, even if AI loses, are you relieved?
However, the first question is: Where is our AlphaGo?
Aluminum Cnc Milling Parts,Custom Metal Parts,Cnc Metal Maachining,Custom Cnc Machining
JIANGSU TONGDE INTERNATIONAL TRADE CO.LTD. , https://www.tongdetrades.com